

AI Enhanced Second Brain
Building a thinking partner

The second brain is not a new idea. Da Vinci kept notebooks. Luhmann built a 90,000-card Zettelkasten. Tiago Forte turned it into a method: capture, organize, distill, express. The shared insight was that your future self is the customer of your current thinking. And without a system, most of that thinking evaporates. What changed with the introduction of MCP servers and AI tools is that the system can now “think back”.
Note: If you’re new to the most powerful way to organize your knowledge base, check out the book Building a Second Brain. You can find a quick summary video here.
The Problem With Every Note-Taking System
Humans think in associations, not hierarchies. You connect a semiconductor supply chain memo to a defense strategy note to a book passage about national sovereignty - because they share structural logic. Traditional tools force this associative thinking into trees. The graph gets flattened into a filing cabinet.
The second brain movement solved the capture problem. Millions of people now have vaults, notebooks, and databases full of highlights, clippings, and notes. But retrieval stayed manual. You had to remember what you wrote, where you put it, and why it mattered. The more you captured, the harder it got to find anything. Past a few hundred notes, most vaults become graveyards - well-organized, rarely revisited.
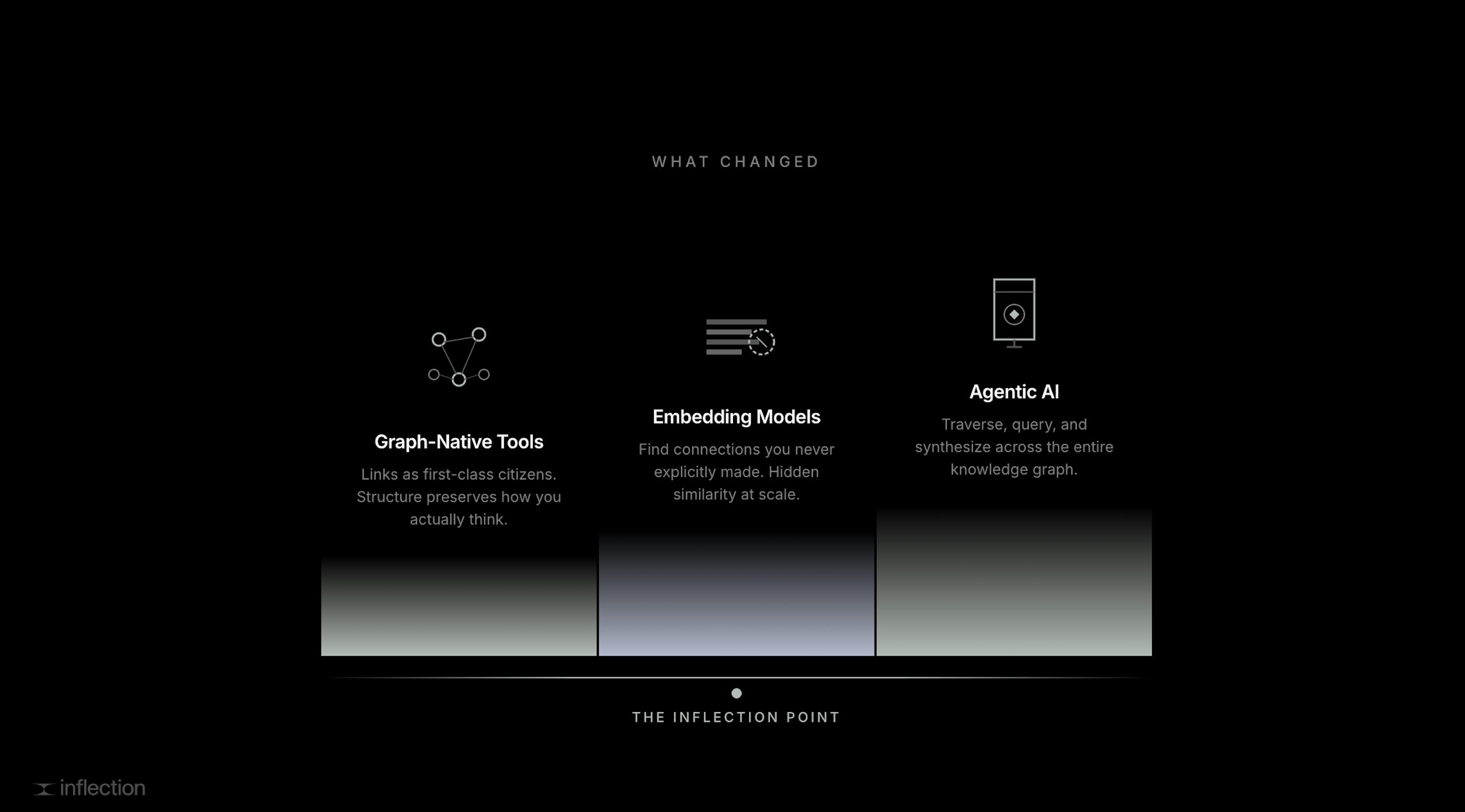
Three things had to converge to change this:
Graph-native knowledge tools (Obsidian, Anytype, Roam) that treat links as first-class citizens, not afterthoughts
Embedding models that find connections you never explicitly made, based on meaning rather than keywords
Agentic AI that can traverse, query, and synthesize across the entire graph in a single reasoning chain
The knowledge tool stores structure. The embedding model finds hidden similarity. The agent reasons over both. Together, they turn a passive archive into an active thinking partner.
What This Looks Like in Practice
One implementation of the above is Cornelius, an open source library you can check out here. A Claude Code agent configured to operate my Obsidian vault (or Anytype or Roam vault) as a second brain. Think of it as a layer cake: me at the top, Claude Code as the general-purpose AI, and Cornelius as a specialized layer underneath with purpose-built tools for knowledge work. It manages notes, extracts insights from what I read, discovers connections between ideas, and synthesizes across months of accumulated thinking.
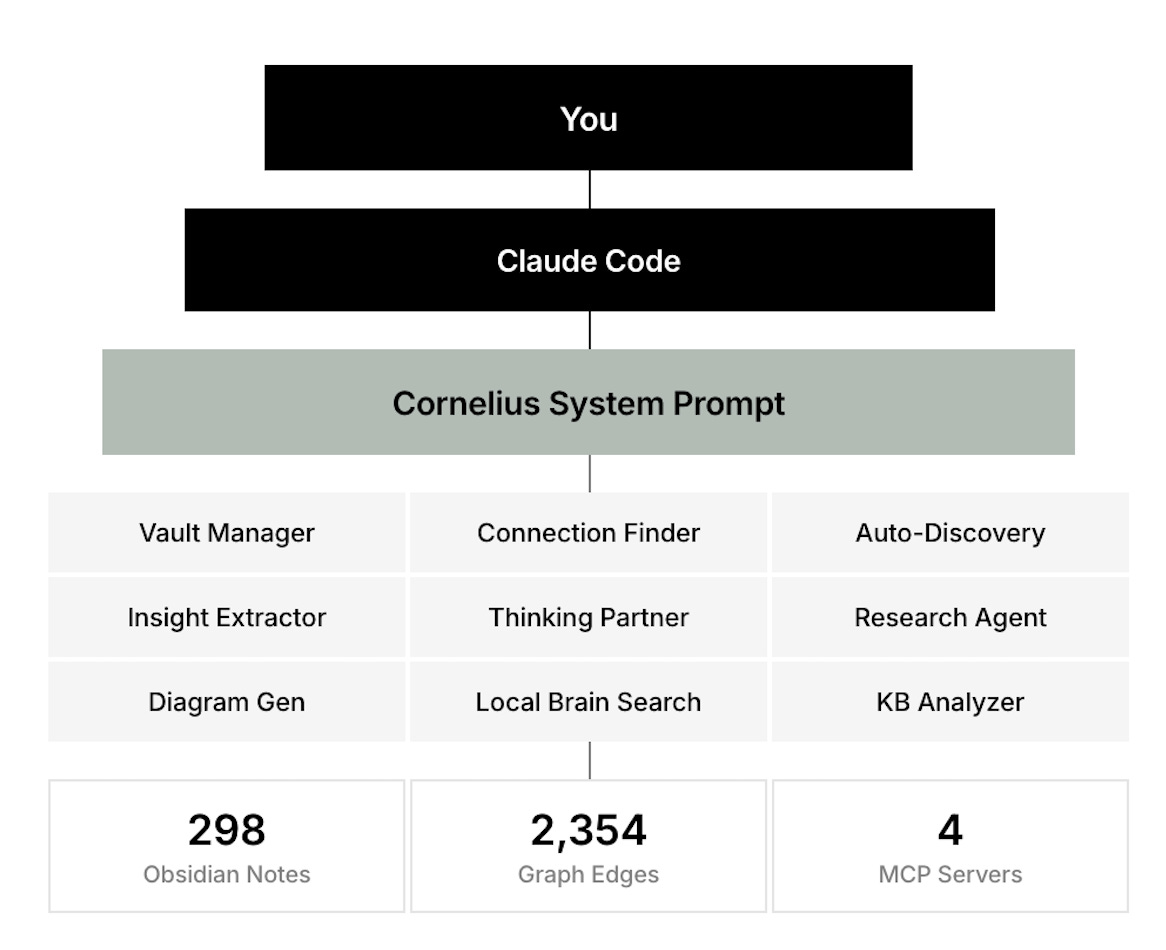
The system currently runs across 298 notes with 2,354 edges in the knowledge graph - roughly half explicit wiki-links I created manually, half semantic connections the AI discovered on its own.
This is a real time glimpse into my second brain:


This stack enables a few things that haven’t been possible before. Here is one out of hundreds of examples from the last few months:
1/ Cross-domain connection discovery. Three portfolio companies - one doing encrypted computation, one building cryptographic silicon, one working on undetectable networking - were written up in separate memos years apart. The system found they form a single architecture. Fully homomorphic encryption is too slow for real workloads, which creates the need for hardware acceleration, but encrypted data still travels on observable networks where metadata alone reveals everything, which creates the need for dark networking. Each company’s binding constraint is the next company’s thesis. The AI traced a constraint cascade across several unrelated investment memos and surfaced an emergent “zero trust compute stack”. Obviously we were aware of those connections when we took the investment decisions but still I was very surprised to see a machine “reason” through seemingly unrelated notes where such connections weren’t made explicit at all.
2/ Synthesized recall across months of work. One question - “what do we know about post quantum cryptography” - pulled together a technical notes on the state of quantum computing, several deal calls with companies working on quantum hardware and software, and book passages about national security infrastructure. Finding those building blocks of knowledge and connect them through years of time and siloed information scattered across different emails, folders, gdrive and CRM tools would have been impossible before. The system reconstructed my accumulated position on the topic in seconds.
3/ Portfolio-level pattern recognition. Once the system identified the zero trust stack, it kept going. It found that the constraint cascade pattern - where one company’s limitation creates the next company’s opportunity - repeated across other portfolio clusters. It surfaced a bridge between the encrypted compute thesis and some of my public market semiconductor positions. That emergent portfolio coherence was invisible until the tool traversed the full graph.
4/ Unsolicited expert network mapping. While researching the encrypted computation space, the system returned the obvious domain experts in my network. Then it added people I didn’t ask about. A professor whose papers were already in my research library, and an engineering lead my partner had met at a conference months earlier who had worked on exactly the problem space I was diving into. The AI mapped my network against my research question and found relevant nodes I had forgotten existed.
The Tool Unification Problem
Knowledge does not live in one app. My research is in Obsidian, Anytype and Gdrive. My relationships and dealflow are in a CRM. My venture portfolio positions sit in Carta. My public market positions in a tracker. The breakthrough here is MCP - Model Context Protocol - which lets the AI agent query across all of them in a single reasoning chain. Any tool with an MCP server becomes part of the second brain. A query can run across our CRM, board decks, founder conversation notes and the knowledge graph simultaneously. Instead of having ten tools I have one intelligence layer that reasons across ten tools. Context switching and knowledge synthesis is done in one pass.
Why the Compounding Effect Matters
A traditional note-taking system has linear returns. Note number 300 is about as useful as note number 30. You still have to find it, read it, and connect it yourself. An AI-enhanced system has compounding returns. Every note you add increases the surface area for future connections. Note 300 can be cross-referenced against all 299 that came before it - semantically, and across domains you would never think to check.
This changes the economics of note-taking. The quality of notes still matters enormously (garbage in, garbage out) but the cross referencing of other notes became exponentially better. Write more, organize less. Capture your thinking in your own words, link where connections are obvious, and let the AI find the rest. In the old world you needed to “build a perfect system.” Now you only need to “feed a good-enough system consistently.”
What This Means for Knowledge Workers
What I’m trying to describe is not just a little productivity hack. It is a structural shift in how individuals can memorize reason at scale. Before long we will see the same patterns emerge on an organizational level too.
A venture investor can maintain deep, synthesized positions across dozens of companies and sectors without losing threads. A researcher can surface cross-disciplinary connections that would take months of literature review. A writer can draw on years of accumulated thinking without re-reading everything they have ever written. A founder can maintain institutional memory as the company scales past what fits in one person’s head.
The key design choices, for anyone building their own version:
Pick a graph-native tool. Obsidian, Logseq, Anytype (portfolio), Roam - the specific tool matters less than its ability to represent links between ideas as first-class objects.
Write atomic notes in your own words. One idea per note, in your voice. Copy-pasted highlights are raw material, not thinking. The AI needs your reasoning patterns, not someone else’s.
Link aggressively. Every explicit link you create strengthens the graph the AI traverses. Over-linking is almost impossible.
Point an AI agent at the result. Use MCP servers, vector search, or agentic workflows to turn the vault from a reference library into a reasoning partner.
The second brain was always a powerful idea I found deeply fascinating. The missing piece was the ability to think with it rather than just store static knowledge in it. That piece is here now, and the gap between people who build these systems and people who do not will compound faster than most realize.
Be aware that many of the technologies mentioned in this post are highly experimental. We set up our system with the support of seasoned engineers and best practices for security and data protection in mind.
How are you building and maintaining your second brain?
Had been on a topic of second brain for a while (and even wrote 2 articles on it here), and this is going to change my direction of thinking a lot in the next quarter.
Mine was a reasonably simple system with a vibe-coded frontend tied to perplexity that was scouring through it, dividing it into knowledge nodes and building graphs on topical insights. The main problem I had and that I am still looking to fix is how to find unknown unknowns - things that I definitely would want to know, but not only I do not, I don't even know they exist for me to know in the first place.